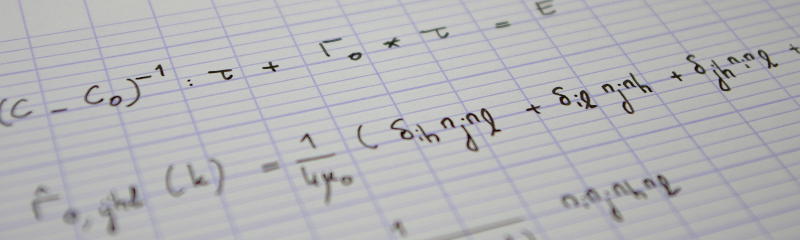
I recently scanned a document as a PDF file, and I wanted to retrieve
the embedded images. I really mean extract the images, and not
convert the pages of the document to images (which would entail loss
of data). There is a nice command-line tool to do that: pdfimages,
which ships with Xpdf. To
extract all images embedded in document.pdf
pdfimages -j document.pdf $PATH-TO-DEST
Where PATH-TO-DEST is the path to a directory where the extracted
images should be stored.